API-Ready Agentic AI
Workflows for Businesses
Pre-Built AI workflows with an API-first architecture, and powered by top AI models. Deployable on cloud and on-prem.
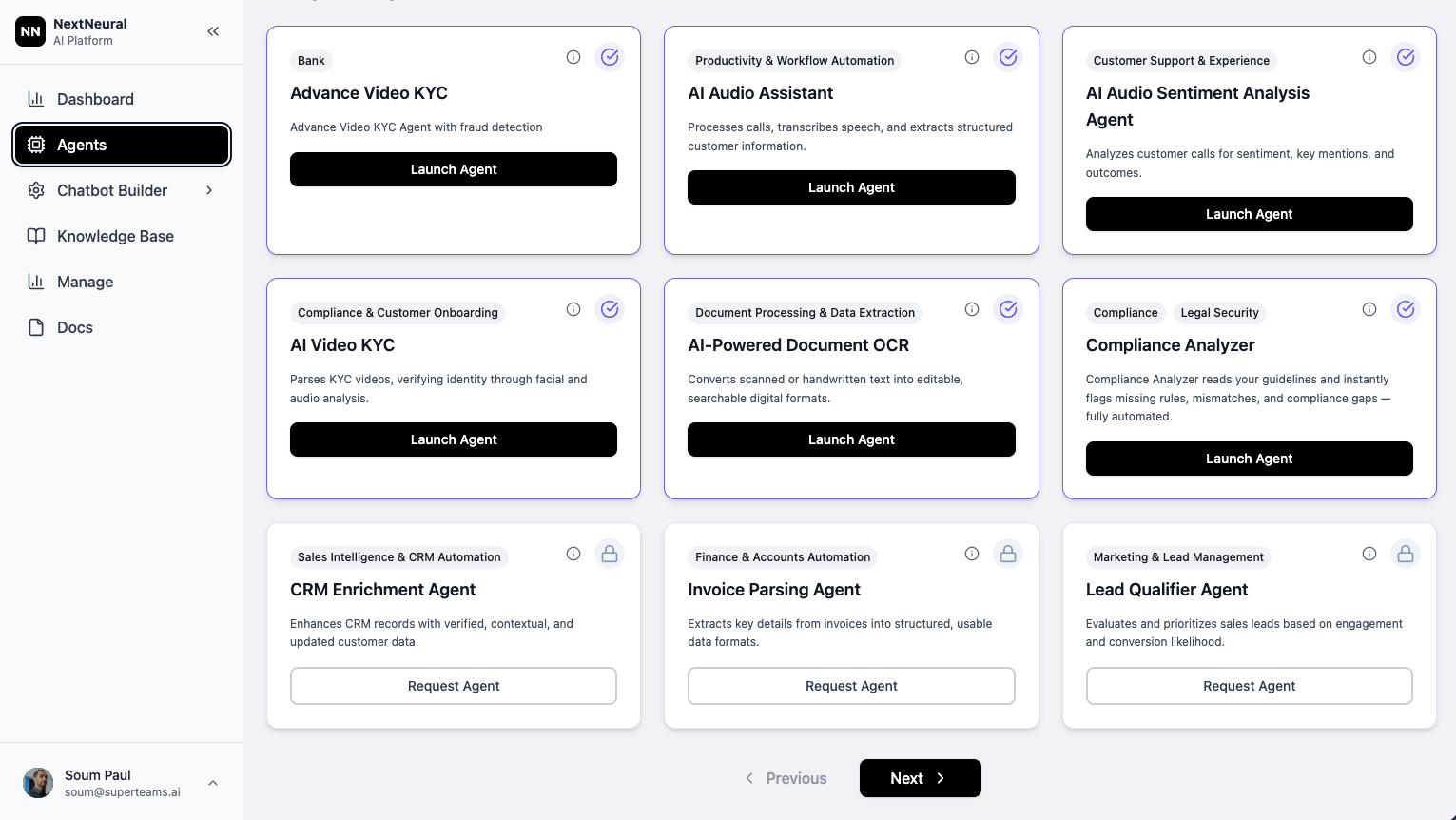
Industry-Ready Agentic Workflows
Scale your operations with pre-built AI agents designed for mission-critical business processes. Modular, secure, and ready to deploy in any environment.
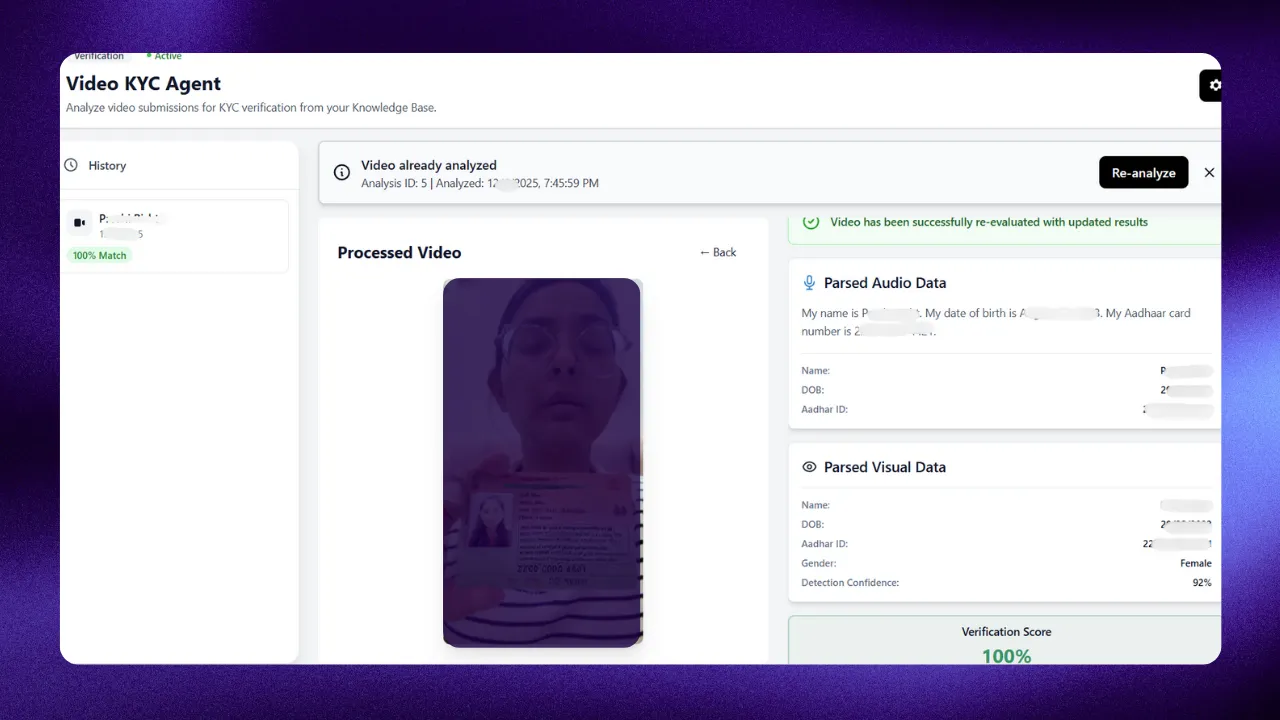
Advanced Video KYC
Verify identities in minutes with AI-powered video KYC and biometric analysis
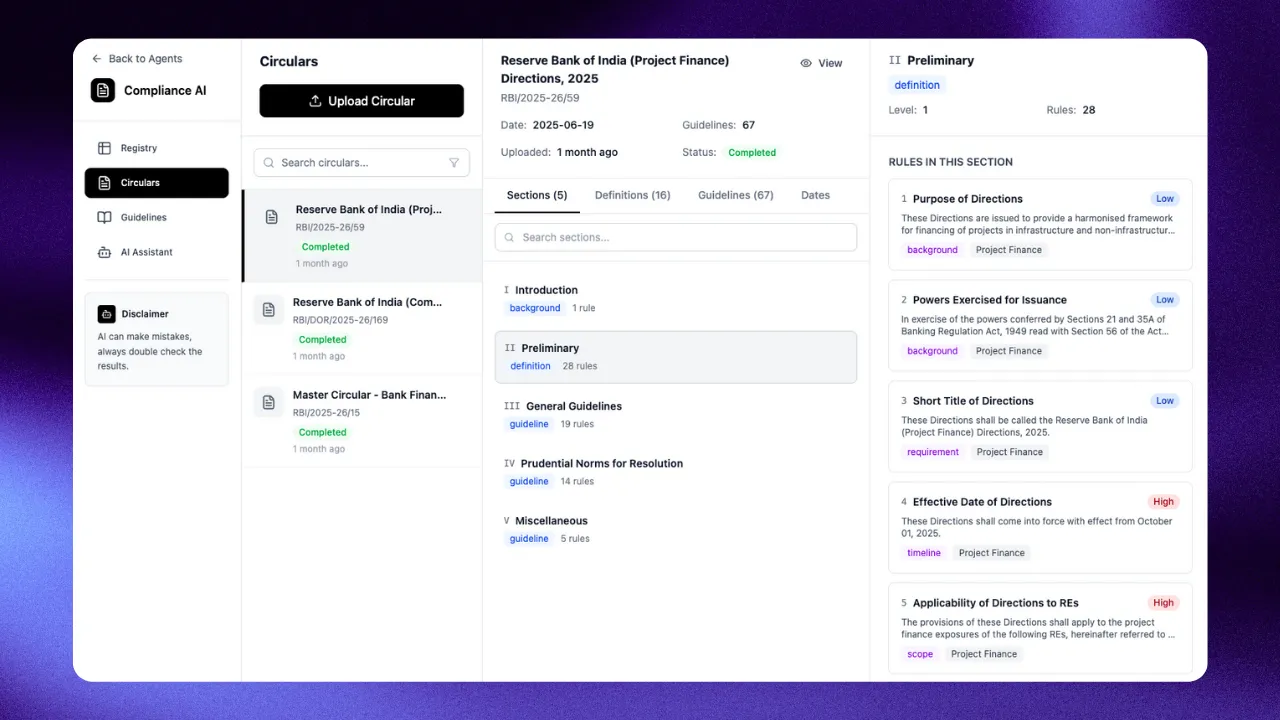
RBI Compliance AI
Stay compliant with real-time RBI regulatory monitoring and automation
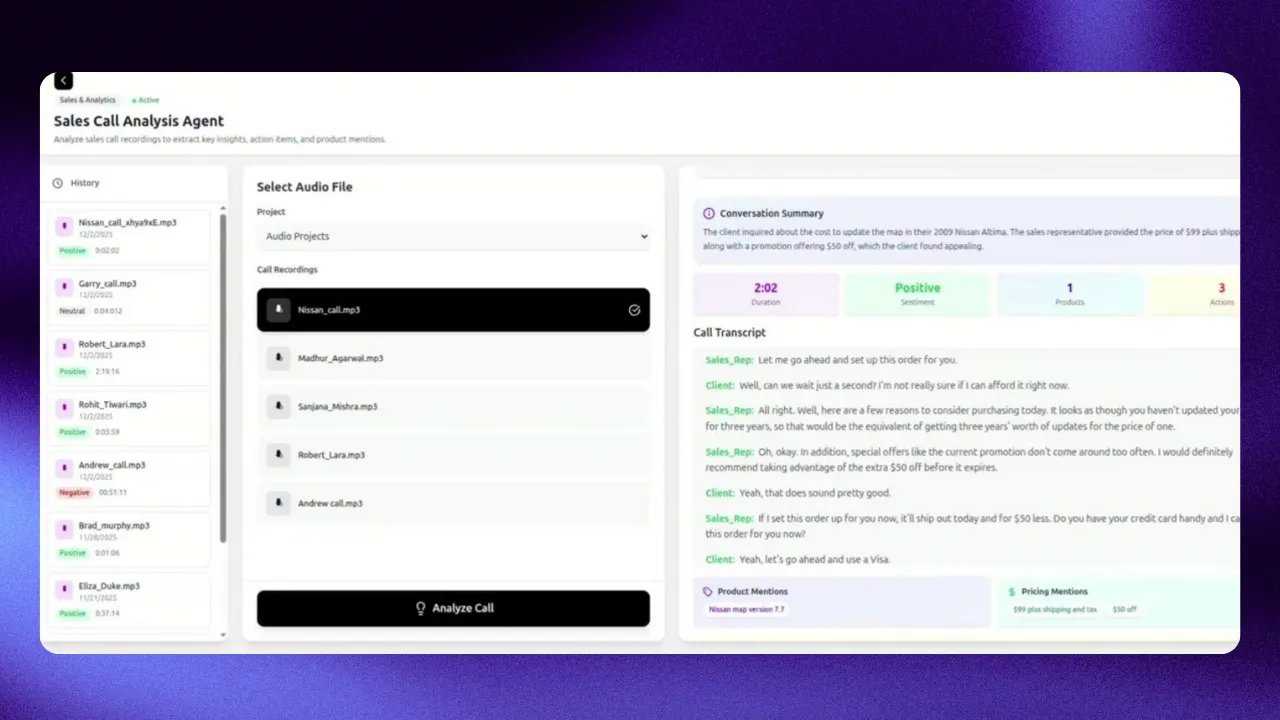
Sales Call Analyzer
Transform sales conversations into actionable insights and coaching data
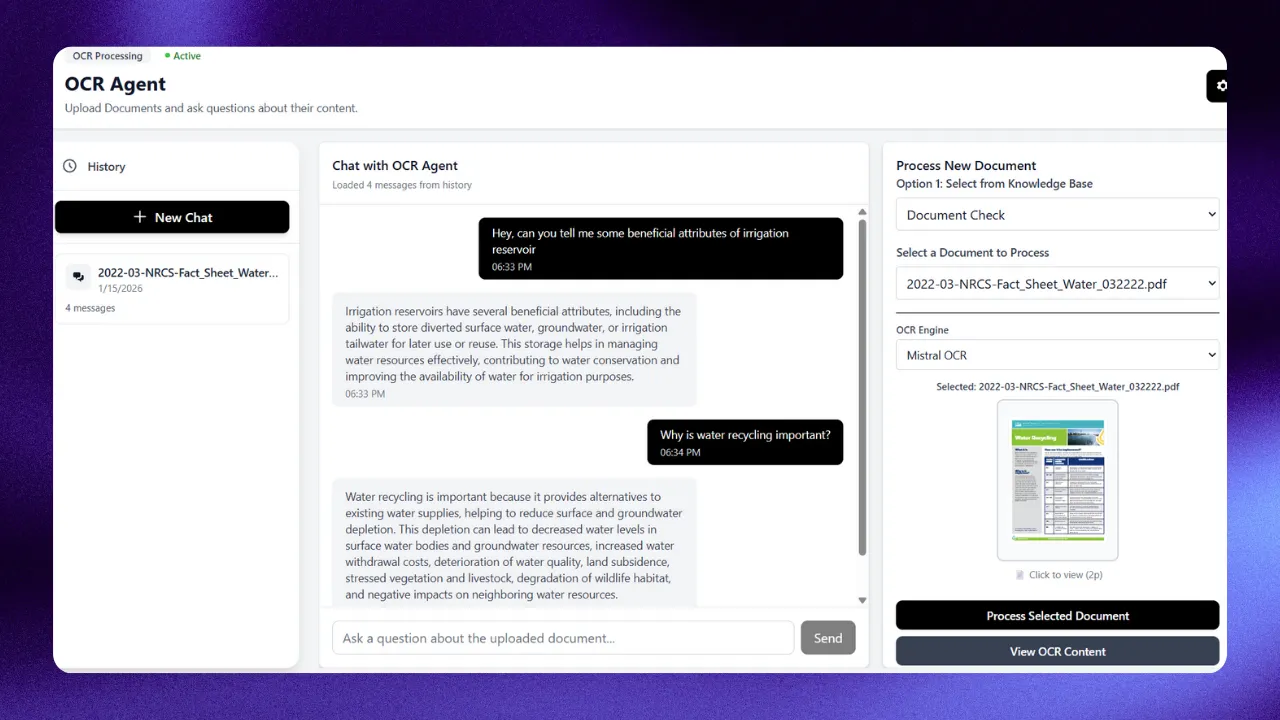
Advanced OCR
TrainingExtract data from any document with 98%+ accuracy, including handwriting
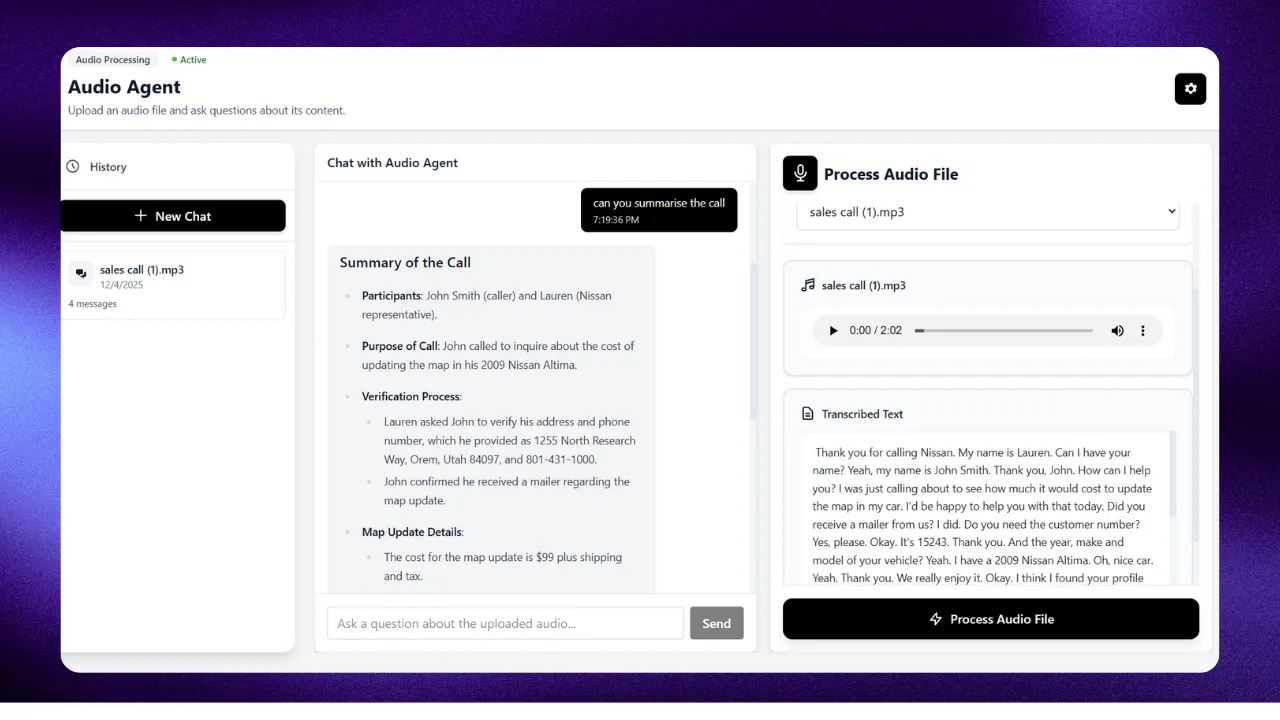
Audio Analyzer
Transcribe, analyze sentiment, and extract insights from audio recordings with AI-powered intelligence
CRM Enrichment
Enrich your CRM with AI-powered conversation analysis and intelligent data completion
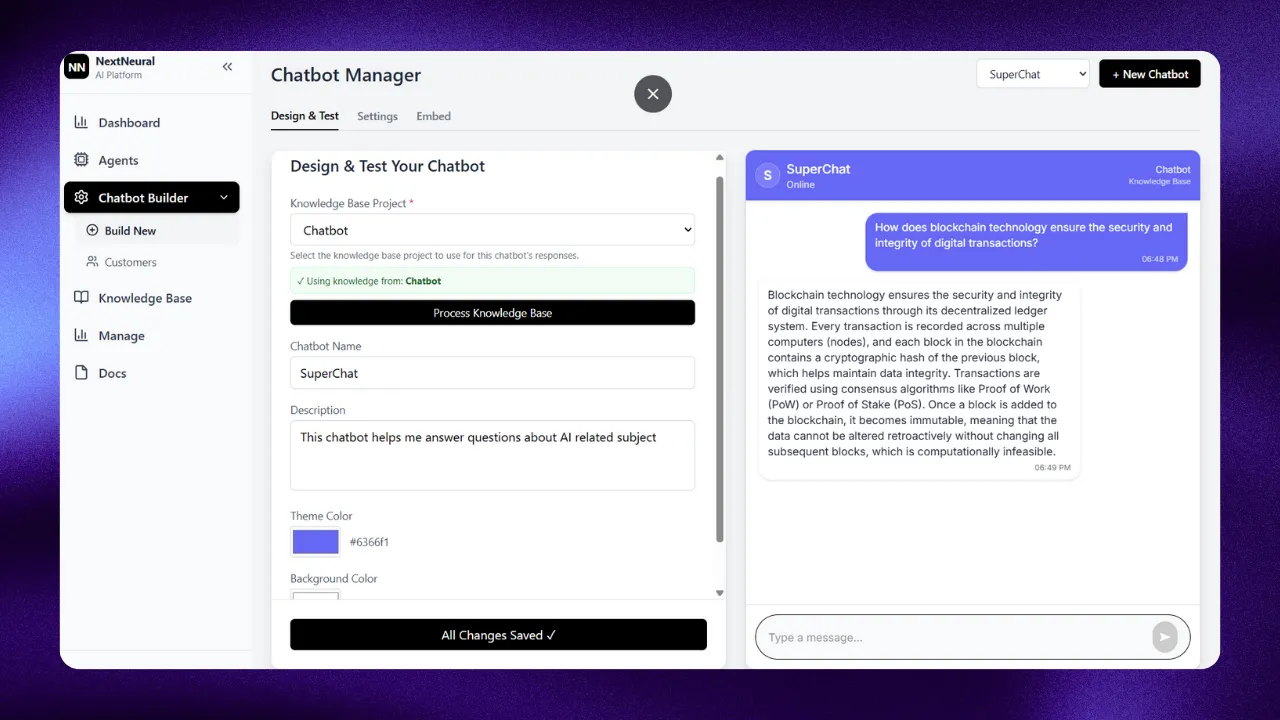
Seamless API Integration
NextNeural's API-first architecture ensures that AI is never an island. Connect our agentic workflows to your existing business logic with standard RESTful endpoints and language-agnostic SDKs.
- RESTful API Endpoints
- Language-Agnostic SDKs
- Standardized Data Schema
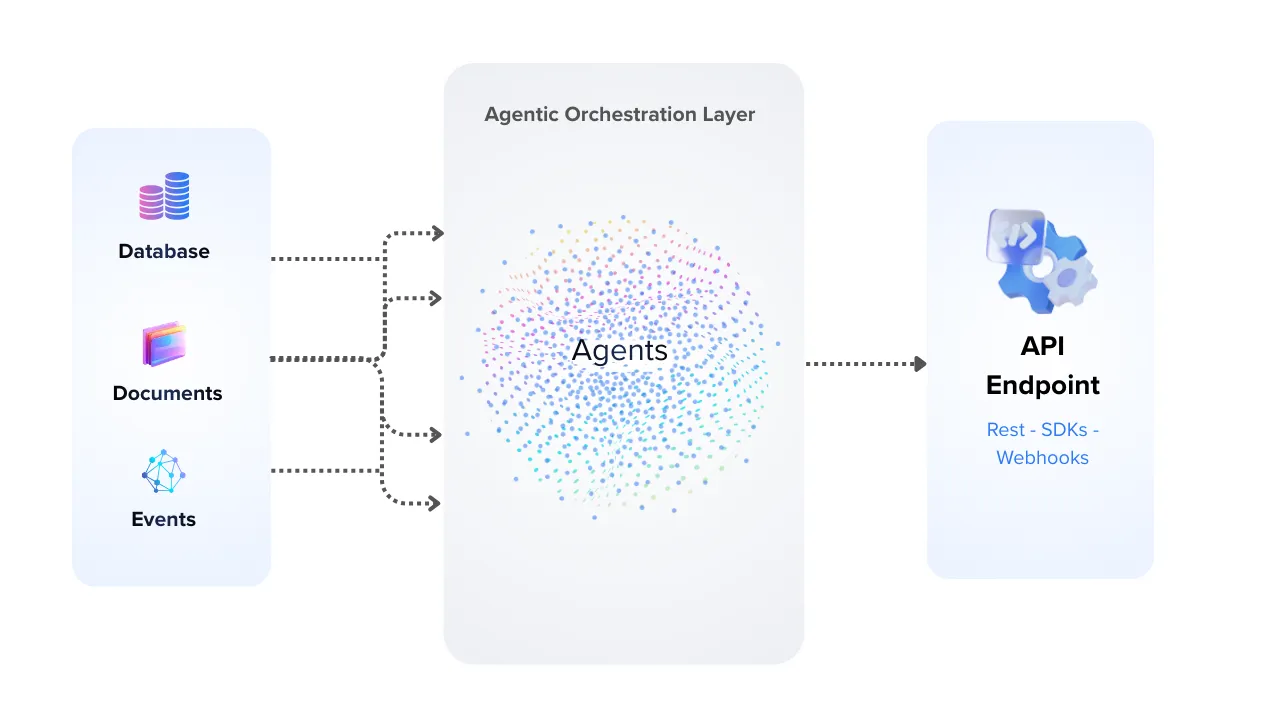
Universal Deployment Architecture
Maintain absolute control over your data residency. Deploy NextNeural agents across public clouds, hybrid environments, or dedicated on-premise hardware without changing a line of code.
- Public & Private Cloud support
- Native On-Premise Deployment
- Full Data Sovereignty
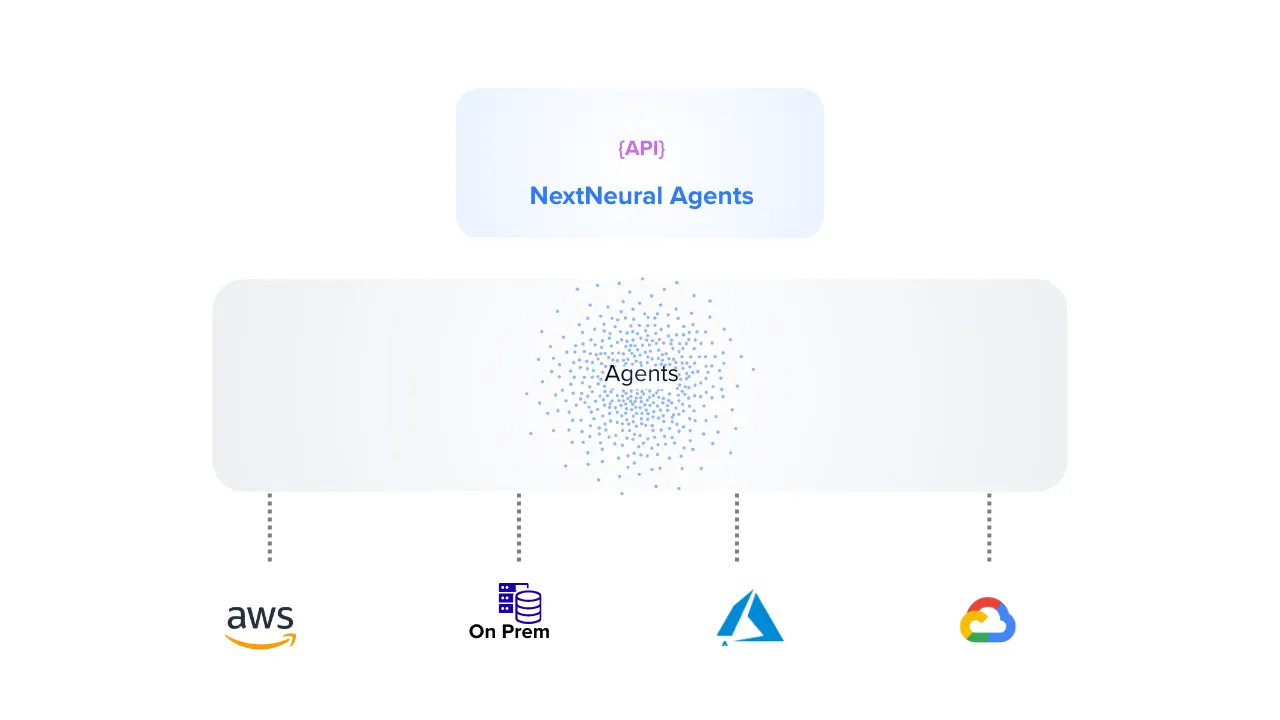
Powered by the World's Best Models
We benchmark and integrate the latest LLMs from OpenAI, Anthropic, and Meta. Our intelligent router automatically selects the optimal model for speed, cost, and complexity based on your specific task.
- Model-Agnostic Architecture
- Intelligent Task Routing
- Performance Benchmarking
Why Top Companies Trust Us
Enterprise Data Native
Connect agents directly to your proprietary data streams. Support for unstructured documents, cloud files, and SQL databases ensures your AI is always in context.
Transparent Sovereignty (BYOK)
Bring your own model keys for complete cost transparency, or deploy entirely on-premise. You maintain absolute control over your infrastructure and spending.
Advanced Neural Retrieval
High-fidelity reasoning powered by Vector Search and Knowledge Graphs. Our retrieval engine ensures agents find the exact truth within millions of datapoints.
Success Stories
Enterprise results delivered by NextNeural agents.
Sovereign RBI Compliance Intelligence
A fast-growing Indian fintech was struggling to keep pace with RBI's rapidly evolving regulatory landscape. Their compliance team spent 60+ hours weekly manually reviewing circulars, extracting requirements, and auditing internal contracts. Critical deadlines were being missed, and they had no systematic way to prioritize high-risk guidelines or track amendments across interconnected regulations.
NextNeural deployed the RBI Compliance AI agent on the fintech's own cloud infrastructure, ensuring complete data sovereignty. The agent intelligently processes RBI master circulars at the guideline level, extracts critical deadlines, maintains cross-references, and automatically audits internal contracts. Role-based access control (RBAC) enabled their legal, compliance, and product teams to collaborate efficiently with appropriate permissions.
Ready to Revolutionize Your Operations?
Join the leading financial institutions using NextNeural to automate the impossible.
Featured In
Recognized by leading industry publications